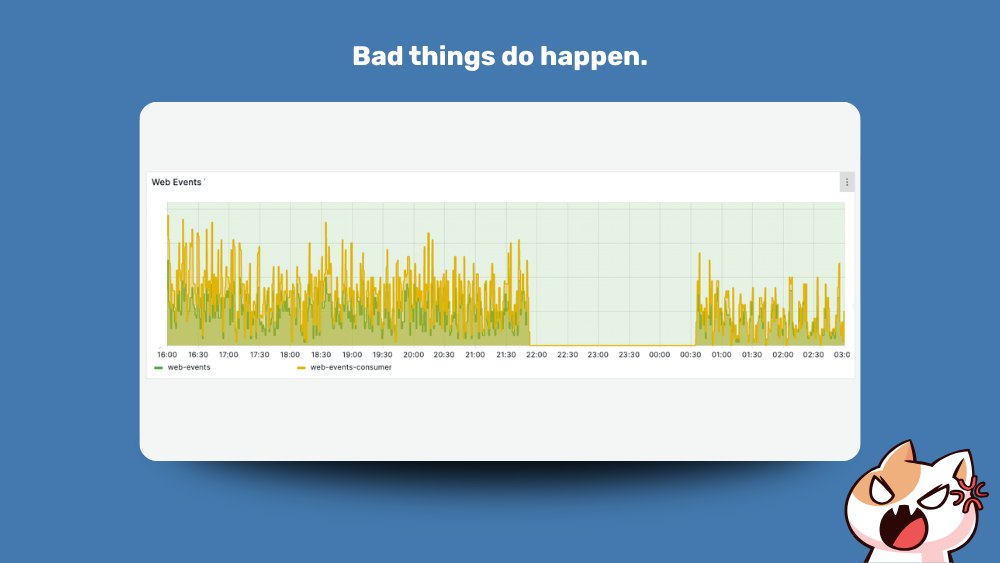
The Saturday the 25th of April 2026 was the worst evening in the whole history of Wide Angle since we launched in November 2021.
First time ever we encountered an incident that resulted in loss of data.
The Background
Couple of months ago, our hosting partner, OVH, warned us about the End-of-Life for current Load Balancing solution for Managed Kubernetes Cluster.
We had plenty of time to plan and prepare and frankly couldn’t wait, as the new offering is a welcome improvement in flexibility and configurability which we previously missed.
We researched OVH documentation and had a plan which thanks to low latency AnyCast DNS would cause seconds of disruption at most.
What should have happened
The process was supposed to be simple.
- We would configure new annotation on Kong Proxy.
- Repoint DNS entry to newly provisioned IP et voila!
What could possibly go wrong, right?
Under the hood, what the platform would do is:
- Provision a gateway instance that is responsible for connecting MKS private network to the outside world.
- A Load Balancer instance would get provisioned,
- A Floating IP would be assigned to our Load Balancer, and finally,
- IP would, via Load Balancer, via Gateway expose Ingresses defined in our cluster.
That was the theory.
What actually happened
Even best laid plans can fall flat when presented with ugly and brittle reality.
Wide Angle MKS was deployed when OVH offering of Kubernetes and Public Cloud was still rapidly evolving.
The private network, vRack, we had configured for our cluster had some legacy defaults which, then by design, had strict separation from the Internet and had Gateway feature disabled.
On the fateful day this proved critical and resulted in the whole migration crashing on the very first step.
Kick Off
Shortly after 10 PM on Saturday, when traffic for most customers dies down, we kicked off the migration.
Almost instantly we hit a problem.
Our subnet within private network refused to provision gateway interface.
At first, it looked like the OVH team has anticipated this very scenario.
The Kubernetes LoadBalancer service initialisation failed with a very useful message and full link to documentation resource which helped us find the relevant setting.
At this point roughly 5 minutes have passed. The original Load Balancer was down and traffic was not flowing.
Despite quickly implementing required change and resolving first error, we hit another snafu and things didn’t look good.
New error, new link to potential resolution.
Quick attempt to rollback was futile. As the legacy Load Balancer was End of Life, the platform refused to re-provision it. Oh no.
At this point events from customers websites were going to a void.
The wait
We found ourselves in a situation where despite having followed all the steps, the gateway was still not getting created.
We immediately created a support ticket. Our support SLA meant that we should hear from someone within 30 minutes.
Without working Load Balancer, while waiting for support, we started looking for fallback options.
Luckily, our nodes do have public IPs, so we could configure Kong Proxy service to leverage the NodePort configuration and use direct access to our nodes and route services internally.
Not the best solution, but it should limit the downtime while we wait for help.
Or so we thought.
The change was fast to implement. I will say what I often repeat: using Kubernetes was and still is one of the best decision we made at the start of the project. These kind of large changes are often a matter of single config line.
The Node IPs were plopped to round-robin DNS and it should just work.
It didn’t.
The nodes configuration did not allow for direct traffic. Our firewall was configured to never allow direct traffic to the node IPs. A security measure which is often a must.
By the time we realized it was firewall messing with our plans, we heard back from OVH support. They are looking into our ticket.
More wait
At this point we made a decision. We accepted the brutal reality that our system is losing events hoping to get resolution in couple of minutes. It felt like a safe move given the issues we could introduce making more changes across network, firewall and configuration.
At this point 40 minutes have passed.
Given that support was on the case, and the fact we expected this to be cloud vendor issue, we opted for sit and wait solution.
Not the most proactive approach, but being often on the other end of support, adding more variables to the investigation by constantly modifying settings, would only add noise and likely delay getting resolution.
The solution – or so we thought
About an hour after opening the ticket we got a callback from the cloud support.
I have to say, when things go wrong, getting a call from a chill and polite person can really calm the nerves and relieve the tension.
The issue was stupidly simple. The IP we selected for our private network gateway was in use. We knew that much from the error message but none of our instances were using that IP. Turns out the IP we selected was reserved for HTTP agent, a service of the Public Cloud solution itself.
We were ecstatic. We had a fix.
All it took was changing Gateway IP from 10.5.128.1 to 10.5.128.2. Yes. Whole down time came to a single digit.
We applied the fix. And it didn’t work.
Our hearts sank.
The solution – this time for real
The help came instantly. The support person called back immediately.
The issue?
Turns out both initial IPs were reserved.
This time we didn’t want to risk it. We picked an IP much further from the contentious range. After that, it was a matter of a few seconds and we had our new Gateway in place. A minute or so later, the fully functional Load Balancer was in place.
What was left was to update DNS zone to new IP and wait for new SSL certificate refresh.
So yes, picking wrong IP (twice) cost us 2 hours of lost customer events. An issue that was resolved in just few minutes.
What We’re Taking Away
Two hours of lost customer data, caused not by a flawed plan but by two consecutively reserved IP addresses. That is a hard pill to swallow.
We prepared well. The migration strategy was sound, our Kubernetes setup proved its worth once again, and OVH support, to their credit, responded within SLA and helped us identify the root cause swiftly. What we didn’t account for was that legacy network configurations from Wide Angle’s early days would quietly set traps for us years later.
The good news: our infrastructure held up in every other respect. No corruption, no cascading failures, and a clean recovery once the root cause was identified. We’ll be reviewing our runbooks to make sure the next migration, however routine it looks on paper, has more fallback options tested in advance.
We’re sorry to our customers for the lost events during this window. We will do better.


