
We at Wide Angle Analytics leverage Apache Kafka for web events processing. It is robust, reliable and wildly popular data processing software. In addition, Kafka is an excellent example of when messaging, stream processing and database elegantly converge into a single solution.
With Kafka, we can quickly and safely scale our operations.
But Kafka has a dirty little secret. Its reliability and rock-solid data persistence capability make governing data retention a challenge. Mixed with GDPR, it can cause a headache.
How does Kafka work, and why does it matter?
When simplified to its barebones, Kafka can be thought of as a persistent append log of entries. These entries can be independently produced and consumed by multiple clients. Because data is always persisted first, the systems allow all connected actors to do their tasks at the pace that suits them.
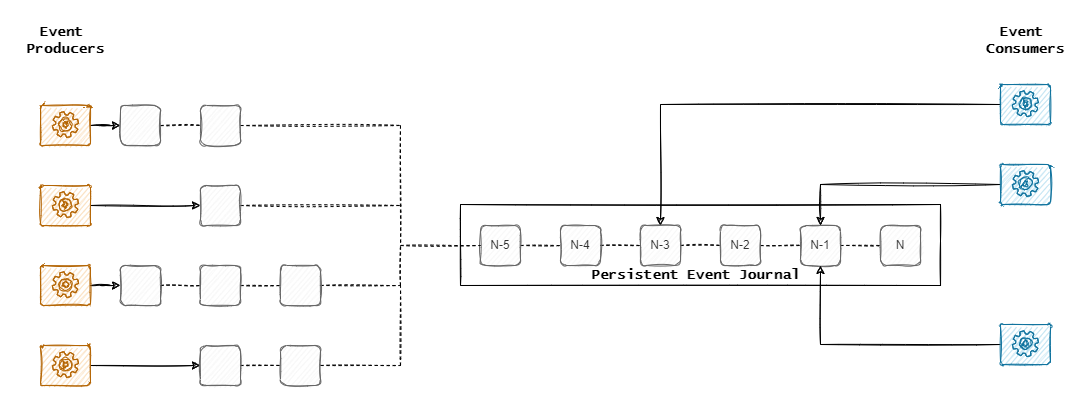
On top of the above concept lies a sophisticated networking and partitioning layer. This layer adds to the versatility of the use cases allowing for scaling on both ends of data pipelines.
It is effortless to add more data. Less so to remove it.
Can you remove data from Kafka?
Yes and no. It really depends on what your data represents. Kafka offers few mechanisms to delete data.
Firstly, data can be set to expire. A topic, a collection of events, can be configured to have events expire after a certain amount of time. This can be seconds, hours, days or never.
Ok, so we can delete data. What’s the problem? This method is very indiscriminate. You cannot delete a specific record. Everything older than the retention period falls off the cliff.

Fortunately, there is a second option. It is called topic compaction. Every event in the topic has a key (as in key-value data store). The key itself does not have to be unique, and multiple events can share the same key. Kafka allows compacting the topic by enforcing uniqueness.
This can be useful to orchestrate a targeted delete operation. Imagine a scenario where the key matches your customer ID. All events for a given customer share the same key. When a customer leaves your product, you can add an extraordinary empty record to the topic and compact it by the key. Leaving only the last, empty record.
As you can imagine, this is not specific enough in many situations.
How can we use Kafka and allow for GDPR compliant processes?
We have to be able to delete the data. You can choose from a few strategies, depending on your use case.
Encrypt, don’t delete
Encryption can be a de-facto deletion solution. For legal purposes, deleting the decryption key and thus rendering data unreadable is equivalent to deleting the information itself.
Let’s use the example from the previous section, where we want to delete all data for a single customer. If the data in Kafka was encrypted with a secret specific to a customer, deleting their secret will equate to data deletion.
We can quickly control what gets deleted and when by making more and more fine-grained secrets.
The penalty? Kafka storage will balloon without proper housekeeping. Full of all unreachable data. Not to mention that handling secrets can quickly get out of hand.
Rewrite topic
Selectively rewriting a topic rewrite can be an effective tactic. In this approach, we create a specialized consumer or a Kafka Stream that reads data from one topic and saves only desired data in the new topic. Once completed, the old one is deleted.
This approach can be highly effective. By filtering the event’s content, we give ourselves a lot of control.
But what if the topic is huge. Say, a couple terabytes? Or what if we have to repeat the process frequently. It could be tough to bake this approach into continuous processes like the ones required by GDPR.
That’s it? Are there no other options?
If neither of the above approaches suits your use case, you have to face the music. You can’t use Kafka as long term data storage.
That’s the solution we settled on at Wide Angle Analytics. We use Kafka’s journal only as short term storage. The topics storing event data are configured with 14 days of data retention. After 2 weeks, the data on the topic expires. Poof, gone from Kafka.
Two weeks is plenty to process any backlog resulting from unexpected data bursts or outages. After that, there is no technical reason to keep that data at hand.
The long term storage is solved by specialized consumers that offload data from the topic onto long term storage. In the case of Wide Angle Analytics, we use OpenStack Swift Object Storage.
Our Long Term Storage process reads data from the topic, encrypts it with a customer-specific secret, annotates the objects with metadata for quick lookup and offloads to an offsite data centre.
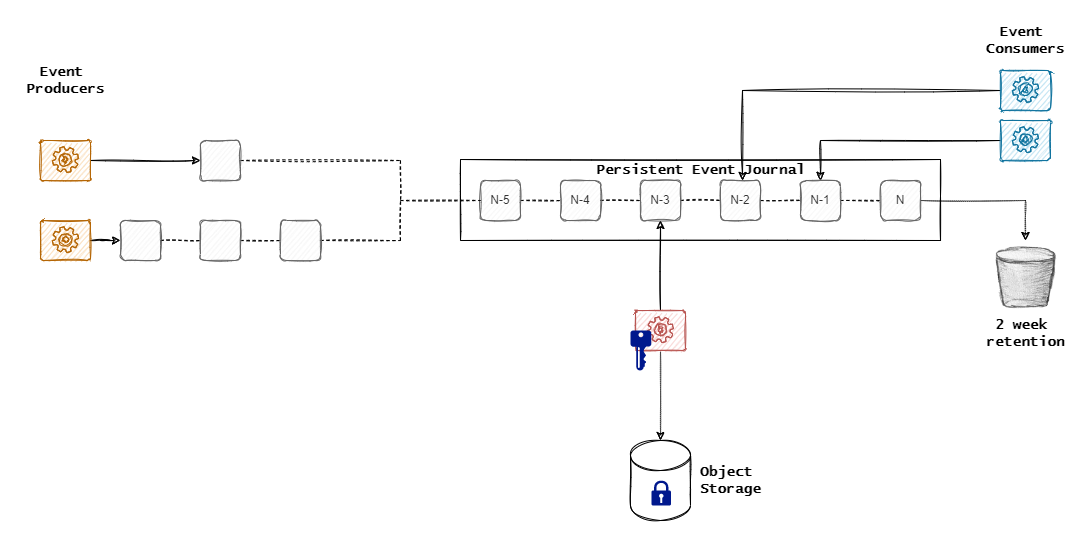
If for whatever reason, we need to replay all data or data for the selected customer, we can restore those events by pushing them back onto the topic.
This is an excellent, conceptually simple solution that fits perfectly with the web traffic data of a GDPR compliant data processor like us.
At the cost of a slightly more complex replay, we gain:
- easy control of data retention,
- small, lean topics which are fast to replicate in the cluster,
- quick and targeted deletes when our customer requests to have their data forgotten, and
- we get an offsite, disaster recovery friendly, fully encrypted customer data backup as a bonus.
GDPR Compliance with Kafka is possible
The solution we arrived at fits nicely with our use case and the data we handle. We rip the benefits of a very reliable, distributed event store that Kafka offers. And we meet our regulatory requirements by choosing suitable long term data storage.
Building a GDPR compliant system capable of processing Personal or Sensitive Data on top of Apache Kafka is possible. But it requires careful engineering and meticulous planning.
No Cookie Banners. Resilient against AdBlockers.
Try Wide Angle Analytics!


